Beginner
•
How to Build an E-Commerce Data Extractor using Playwright and Emergent
How to build an E-commerce Data Extractor using Emergent and Playwright.
Written By :

Naman Madhur

In this tutorial, you’ll learn how to build an E-commerce Data Extractor using Emergent and Playwright. This app will allow users to input the URL of any e-commerce product or search results page - such as Amazon, Flipkart, or Nike - and automatically extract key details like the product name, price, rating, and number of reviews.
You’ll see how Playwright is used under the hood to open a browser, navigate to the provided link, and collect data from product listings in real time. Emergent will then structure and display the extracted data in a clean, copyable table format right on your web app.
By the end of this tutorial, you’ll have a working web-based data extractor that can:
Fetch and parse data from multiple e-commerce sites
Display results instantly in a structured, scrollable table
Allow users to copy or export extracted data with one click
Here's what you will be able to build by the end of this tutorial:
Let’s get started by setting up the project on Emergent.
What is Playwright and How It Powers Our Data Extractor
Before we start building, it’s important to understand the core technology that makes this project possible - Playwright.
What is Playwright?
Playwright is an open-source browser automation framework created by Microsoft. It allows developers to control real browsers (like Chrome, Firefox, and Safari) programmatically - meaning you can open pages, click buttons, fill forms, or extract information just as a human would.
Unlike traditional web scraping tools that simply download raw HTML, Playwright interacts with live websites - including those built with JavaScript - making it far more powerful and accurate for extracting modern web content.
Here’s what makes Playwright special:
Cross-browser automation: Works across Chromium, Firefox, and WebKit.
Handles dynamic pages: Waits for elements to load and executes JavaScript automatically.
Headless browsing: Runs without showing a visible browser window.
Stealth automation: Can mimic human-like browsing to avoid detection by anti-bot systems.
Why We’re Using Playwright
Most e-commerce websites - such as Amazon, Flipkart, or Nike - rely heavily on JavaScript to render product details dynamically. If you try scraping them with simpler tools like requests or BeautifulSoup, you’ll often end up with incomplete or missing data.
That’s where Playwright shines. It:
Opens a real browser session
Loads all dynamic content (prices, ratings, reviews, etc.)
Extracts structured data directly from rendered pages
This makes it ideal for building a Data Extractor that can:
Load product listing pages
Wait for all product elements to appear
Extract product details accurately
Handle multiple sites with flexible selectors
How Playwright Fits into Emergent
When you describe your app on Emergent, the backend automatically integrates Playwright into a FastAPI-based Python server.
Here’s what happens behind the scenes:
A user pastes a product URL into the web app.
The backend launches a Playwright session in headless mode.
Playwright navigates to the given URL and waits for content to load.
It extracts product names, prices, ratings, and reviews using predefined selectors.
The backend sends this structured data back to the frontend - which Emergent formats into a clean, interactive table.
This seamless integration means you never need to configure Playwright manually - Emergent handles everything.
In short, Playwright acts as the engine of your E-commerce Data Extractor, bringing real-time, reliable data from the web straight into your app.
Building the E-commerce Data Extractor on Emergent
Now that we’ve covered what Playwright is and why it’s perfect for this use case, let’s move to the most exciting part - actually building the E-commerce Data Extractor on Emergent.
Emergent allows you to describe your app idea in plain English, and its multi-agent system automatically generates all the code, backend logic, and frontend UI. You don’t have to manually set up Playwright or configure servers - the agents take care of that for you.
Writing the Prompt
Here’s the exact prompt used to build the E-commerce Data Extractor:
Prompt:
Once you submit this prompt, the Agent begins by asking a few clarifying questions to ensure the app aligns with your intent.
Answering the Agent’s Clarifying Questions
Before generating code, the agent will ask you a few questions. Please note, the questions will be different for every user. These are the questions the agent asked me:
Playwright Integration:
Should Playwright run on the backend (server-side scraping) or use the browser-based MCP tools?
Chose backend (server-side scraping) for better reliability.E-commerce Sites Coverage:
Which sites should the extractor prioritize?
Stared with Amazon and Flipkart, and later expand to Etsy and eBay.Export Format:
For the “Copy to Clipboard” feature, what format should be supported?
Select both CSV and plain text for flexibility.Error Handling:
What happens when a URL is invalid or scraping fails?
Chose detailed extraction logs for debugging.
After you answer the agent’s questions the agent gets to building the tool. This is how it looks like (we will be improving this further:
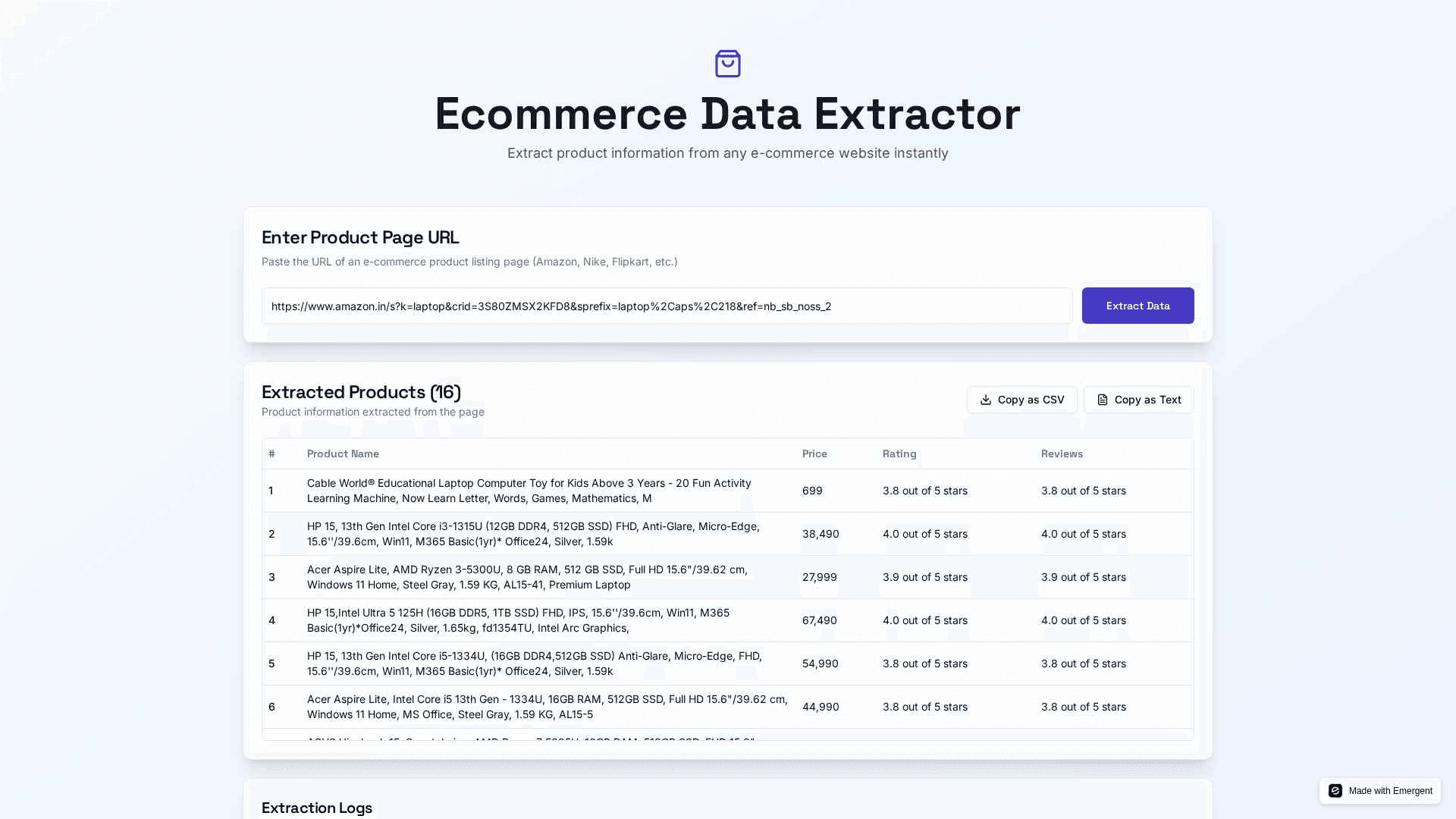
Debugging and Improving with Extraction Logs
Once you deploy the first version of your Ecommerce Data Extractor, you might notice that some websites - like Amazon (in my case) - occasionally fail to return data. This is completely normal in web scraping since different sites use different structures or anti-bot protections.
To make debugging easier, we added an Extraction Log feature inside Emergent. Each time Playwright attempts to scrape a page, it generates a log entry that records:
The URL being scraped
The extraction status (success or failed)
Any visible error messages or HTTP codes returned by the page
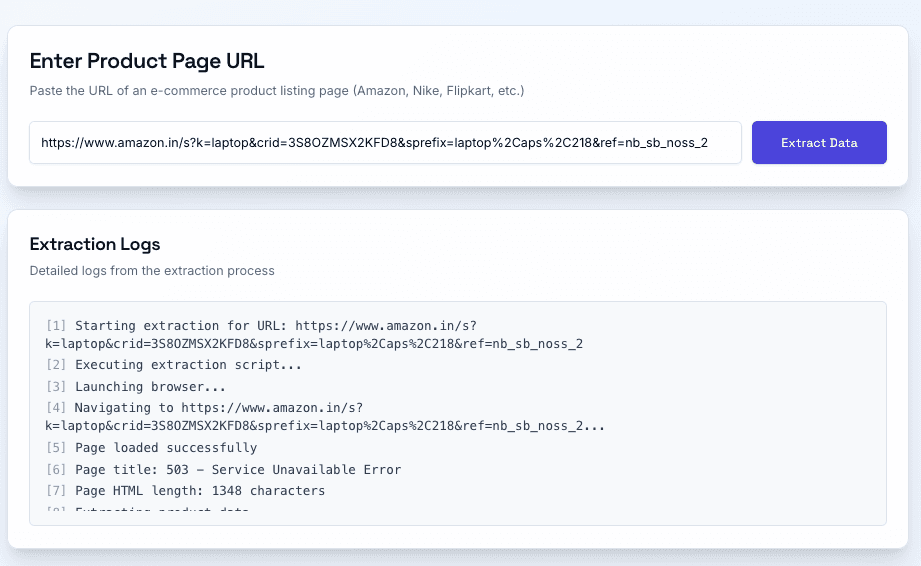
When a scrape fails, you can simply upload the log or screenshot (as shown below) into Emergent. The agent will automatically analyze the logs, identify the root cause, and suggest (or even apply) fixes directly to your backend script.
For example, when the Amazon scrape returned a “503 Service Unavailable” error, the agent quickly diagnosed that it was an anti-bot protection issue. It then updated the /app/backend/server.py file with better request handling to bypass the restriction safely.
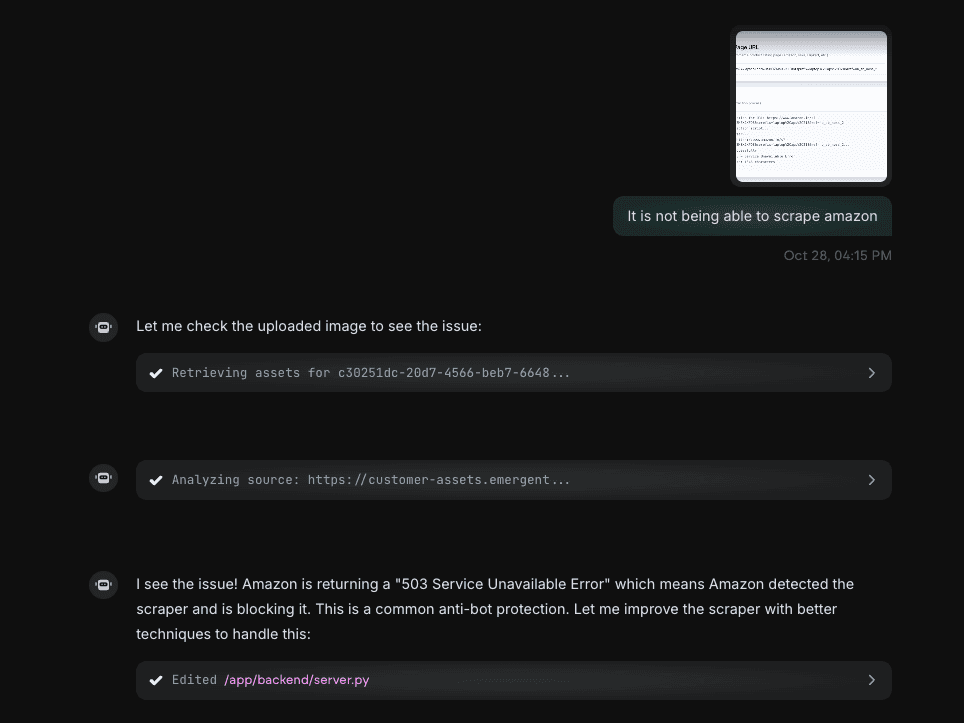
Over time, as you feed more failed URLs and logs back into Emergent, your extractor becomes smarter - progressively supporting more websites and improving its reliability with every iteration.
Adding Feature Controls to the Ecommerce Data Extractor
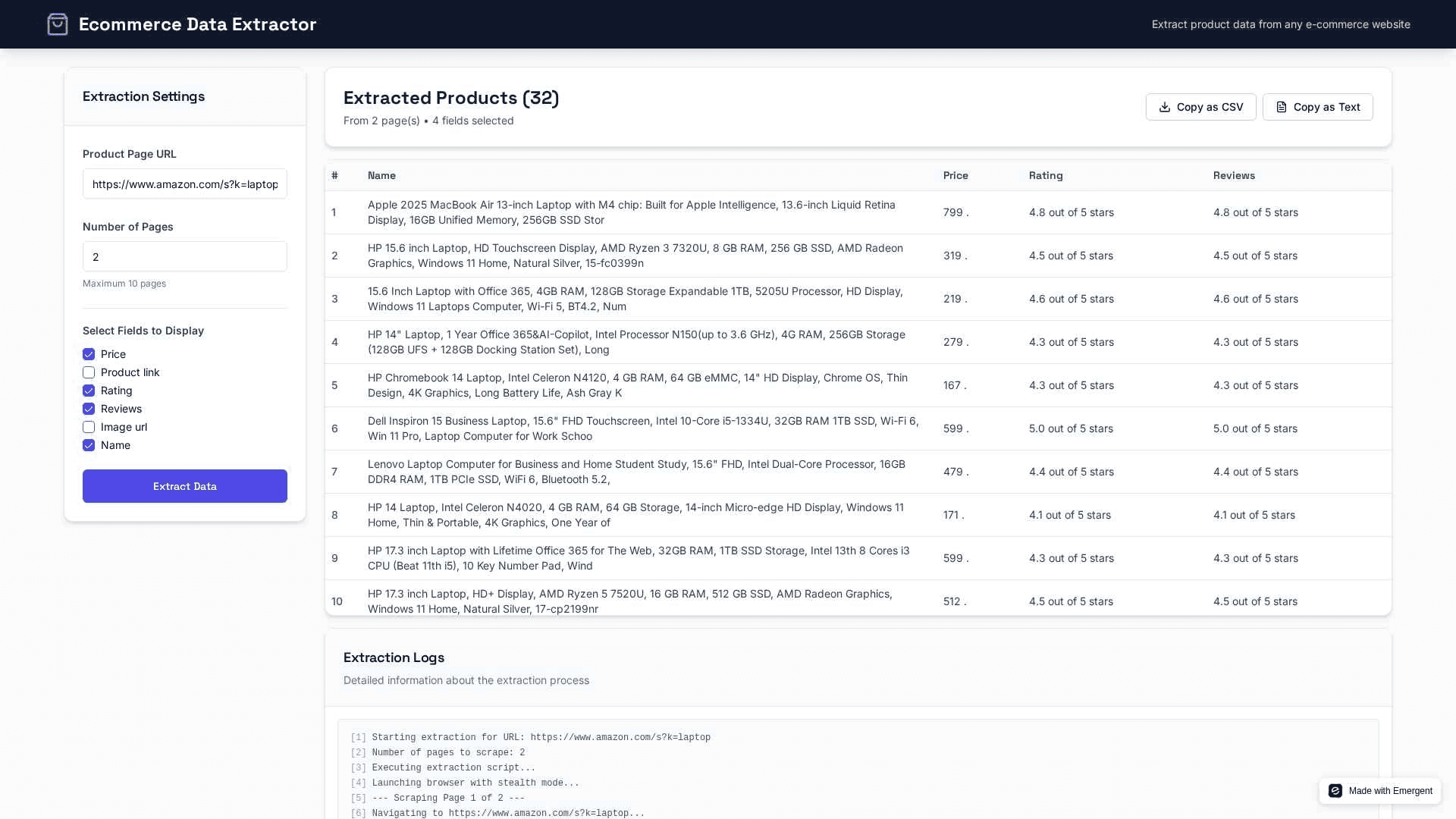
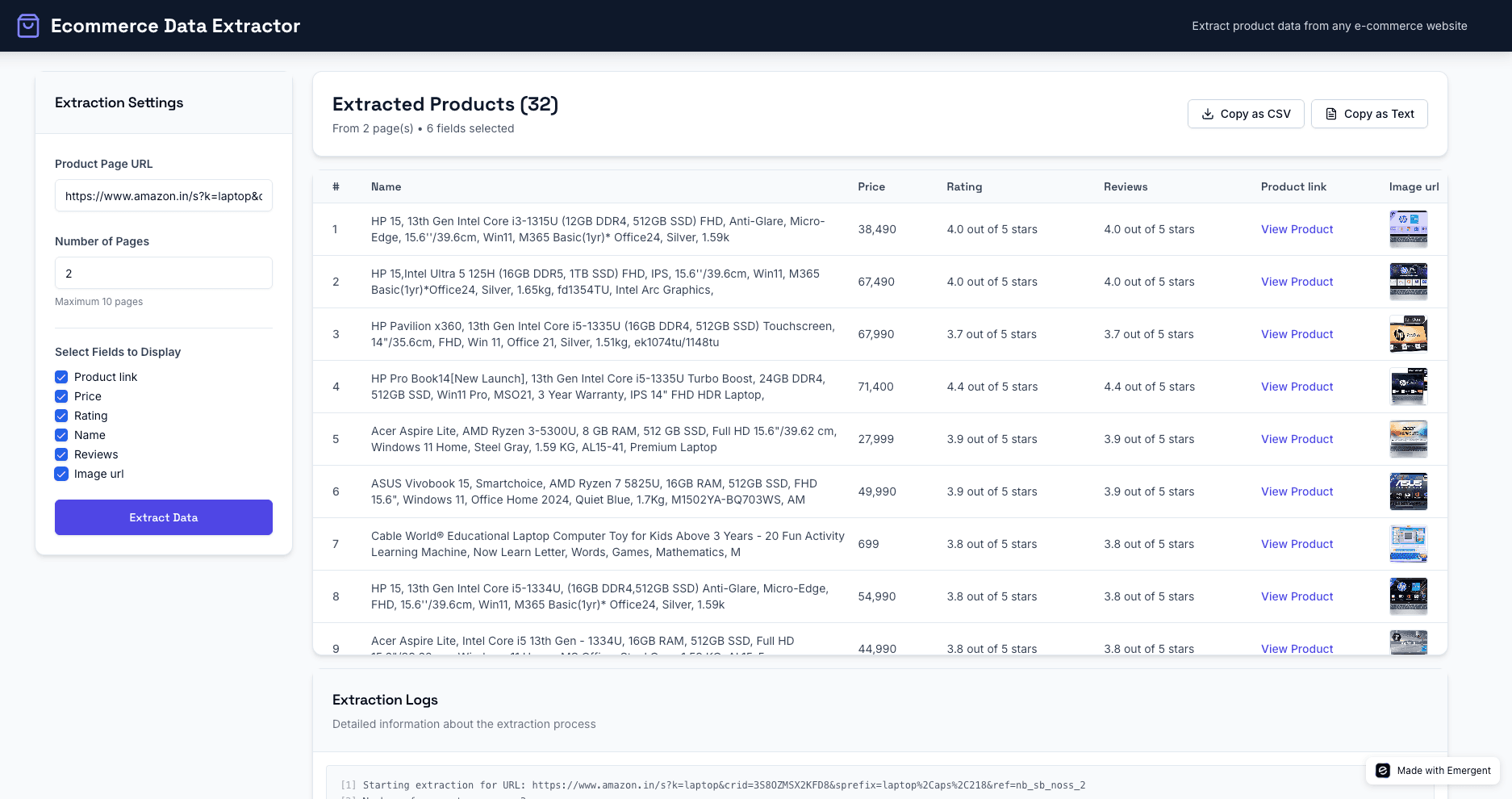
Once the base version of the Ecommerce Data Extractor was up and running, we made it more interactive and user-driven by adding two key capabilities - field selection and multi-page extraction. These features make the app feel like a real data dashboard rather than a simple scraper.
1. Select Which Fields to Display
Although Playwright already extracts all key fields - Product Name, Price, Rating, Reviews, Image URL, and Product Link - the user might not always need to see everything.
To give users control over what appears in the results, a new “Select Fields to Display” panel was added in the left sidebar.
Users can check or uncheck fields like:
Product Link
Price
Rating
Name
Reviews
Image URL
When the user makes changes, the frontend dynamically updates the displayed table.
No new scraping happens - all data has already been fetched by Playwright. The UI simply filters the table view to include or hide the relevant columns.
This approach keeps the extraction fast while still offering flexibility.
2. Scraping Multiple Pages
Since most e-commerce platforms paginate their listings, we introduced a “Number of Pages” input option. Users can specify how many pages (up to 10) they want the scraper to go through.
When extraction begins:
Playwright automatically handles pagination.
It moves through each page, waits for products to load, and collects data.
The data is combined into a single structured table, which displays a count like “Extracted Products (32)” at the top.
This gives users the ability to pull larger datasets with a single click - ideal for bulk comparisons or price monitoring.
Wrapping Up - Making Your Data Extractor Even Smarter
With just a few lines of instruction and Playwright powering the backend, you’ve built a fully functional Ecommerce Data Extractor that can scrape, display, and filter product data from multiple e-commerce websites - all inside Emergent.
You now have a working application that:
Extracts structured product data from sites like Amazon, Flipkart, or Nike
Lets users choose what data fields to display
Supports multi-page scraping
Includes real-time extraction logs for transparency and debugging
But this is only the foundation. Emergent makes it incredibly easy to extend this project further - here are a few directions to explore:
What You Can Add Next
1. Turn It into a Chrome Extension
You can convert this web app into a Chrome Extension using Emergent’s Chrome Extension builder.
This would allow users to open any e-commerce product page and extract data directly from their browser with one click - no need to open the full web app.
Imagine browsing Amazon and instantly seeing a sidebar showing price, rating, and review counts - that’s exactly what you can do with Emergent’s extension workflow.
2. Add AI-Powered Insights with Emergent’s LLM Key
Instead of just displaying raw data, you can plug in Emergent’s Universal LLM Key to make the extractor intelligent.
For example, once the data is scraped, the AI can:
Summarize top deals (“These 3 laptops offer the best price-to-performance ratio”)
Highlight outliers or patterns (“Average rating dropped significantly on page 3”)
Recommend products based on preferences you define (“Show laptops under ₹50,000 with rating above 4.5”)
This transforms your scraper from a data extraction tool into a data intelligence assistant.
3. Add Export and Analytics Features
Enhance usability by letting users:
Download data directly as Excel or JSON files
Save extraction sessions for later reference
Visualize price trends across multiple pages using simple charts
Emergent handles backend setup, database storage, and visualization libraries automatically - so all you need to do is describe the feature.
4. Automate Scheduled Extractions
You can even add a scheduling feature that automatically re-runs the scraper daily or weekly and emails you a summary of new product listings or price changes.
Perfect for tracking discounts or performing competitor analysis.



