

Anthropic shipped Opus 4.7 on April 16, 2026, and the launch-day chart looked clean. 12 of 14 benchmarks up, same price as 4.6, indicating that upgrading is a no brainer. But spend ten minutes on r/ClaudeAI and you'll find a different story. One post titled "Claude Opus 4.7 is a serious regression, not an upgrade" cleared 2,300 upvotes in 24 hours, mostly because long-context recall took a real hit. BrowseComp dropped 4.7 points too. The tokenizer changed in a way that can quietly inflate your bill by up to 35% on the same input. And Anthropic's own migration guide tells you to re-tune your prompts before switching. None of that fits on a launch chart, but all of it shows up in production.
So we put together the comparison we wish we'd had on day one. We ran both models head-to-head on the work that actually matters (coding, reasoning, long-document recall, instruction precision, and strategic pushback) then cross-checked everything against what Anthropic, the launch partners, and the community have reported since. By the end, you'll know exactly where 4.7 wins, the three places 4.6 still beats it, what the migration will cost you in prompt re-tuning and tokenizer math, and whether to upgrade, hold, or run both.
Claude Opus 4.7 vs Opus 4.6: Key changes
The biggest shift in Opus 4.7 is reliability on long, complex tasks. Anthropic says you can now hand off harder coding work that used to need close supervision.
Four changes matter most. Let’s have a look at them.
1. Improvements in multi-step reasoning
Opus 4.7 holds the thread better when prompts stack assumptions on top of each other. The most consistent finding from Anthropic's launch partners is that 4.6 tends to drop subtasks midway through long agentic sequences, while 4.7 carries them through to completion.
The mechanism behind this is something Anthropic calls self-verification. Per Anthropic's launch post, the model "devises ways to verify its own outputs before reporting back." In plain terms, it checks its own work. It might write a test against its own code, run a sanity check on its math, or generate a proof before calling a task done.
For builders, this matters most when tasks involve 10+ steps. The drift that used to creep in around step seven or eight is much less of a problem now.
2. Changes in coding and debugging behavior
Opus 4.7 needs fewer tries to land a working fix. Notion measured a 14% improvement over Opus 4.6 on internal coding tasks, with fewer tokens used and roughly a third of the tool errors. Rakuten reported that 4.7 resolves 3x more production tasks on its internal benchmark compared to 4.6.
The underlying change is fewer retries and tighter outputs. Where 4.6 might generate a fix, fail a test, regenerate, and try again, 4.7 tends to get it right on the first or second pass. CodeRabbit's analysis on code review tasks found that Opus 4.7 commits to fewer, more confident recommendations instead of producing ten options and leaving the developer to choose.
For teams shipping AI tools for developers and AI tools for startups, this directly cuts credit and token costs. Fewer errors and fewer retries add up to lower cost per task, even though the per-token price hasn't changed.
3. Better context retention across long inputs
Opus 4.7 remembers earlier parts of a conversation more reliably, especially in long, multi-session work. Anthropic says the model is better at using file-system-based memory: it can hold onto notes saved between sessions when it has access to persistent storage.
In practice, this shows up two ways. First, long conversations stay on track further in. Agents that used to forget their own notes around the 50k-token mark now keep the thread going longer. Second, agents that read and write to a project memory file between sessions behave more like they actually remember what happened yesterday.
For builders running AI workflow automation platforms or AI research tools that chain work across sessions, this is the most underrated improvement in the release.
4. More stable and predictable output formatting
Opus 4.7 does exactly what you ask, no more, no less. This is both the best and the most disruptive change in the release.
Anthropic's own migration guide puts it plainly: "Opus 4.7 takes the instructions literally. Users should re-tune their prompts and harnesses accordingly."
At low and medium effort levels, the model sticks tightly to what you asked. If your prompts relied on Opus 4.6 reading between the lines and filling in things you didn't explicitly ask for, you may get less output than expected.
The upside is predictability. If you ask for JSON, you get JSON. Tool call formats are stricter. The model won't silently add sections you didn't request. The downside is migration work: prompts written loosely for 4.6 need to be made more specific for 4.7. Independent testing confirms this trade-off. More reliable in the long run, but with real prompt-tuning cost in the short term.
Performance benchmark: Opus 4.7 vs Opus 4.6
The benchmark story is simple. Opus 4.7 wins on 12 of 14 published tests, with the biggest gains in coding, AI agent tool use, and visual reasoning. Where it doesn't win, it loses noticeably, especially on web search.
All numbers below come from Anthropic's official Opus 4.7 launch announcement, with independent checks from Artificial Analysis where available.
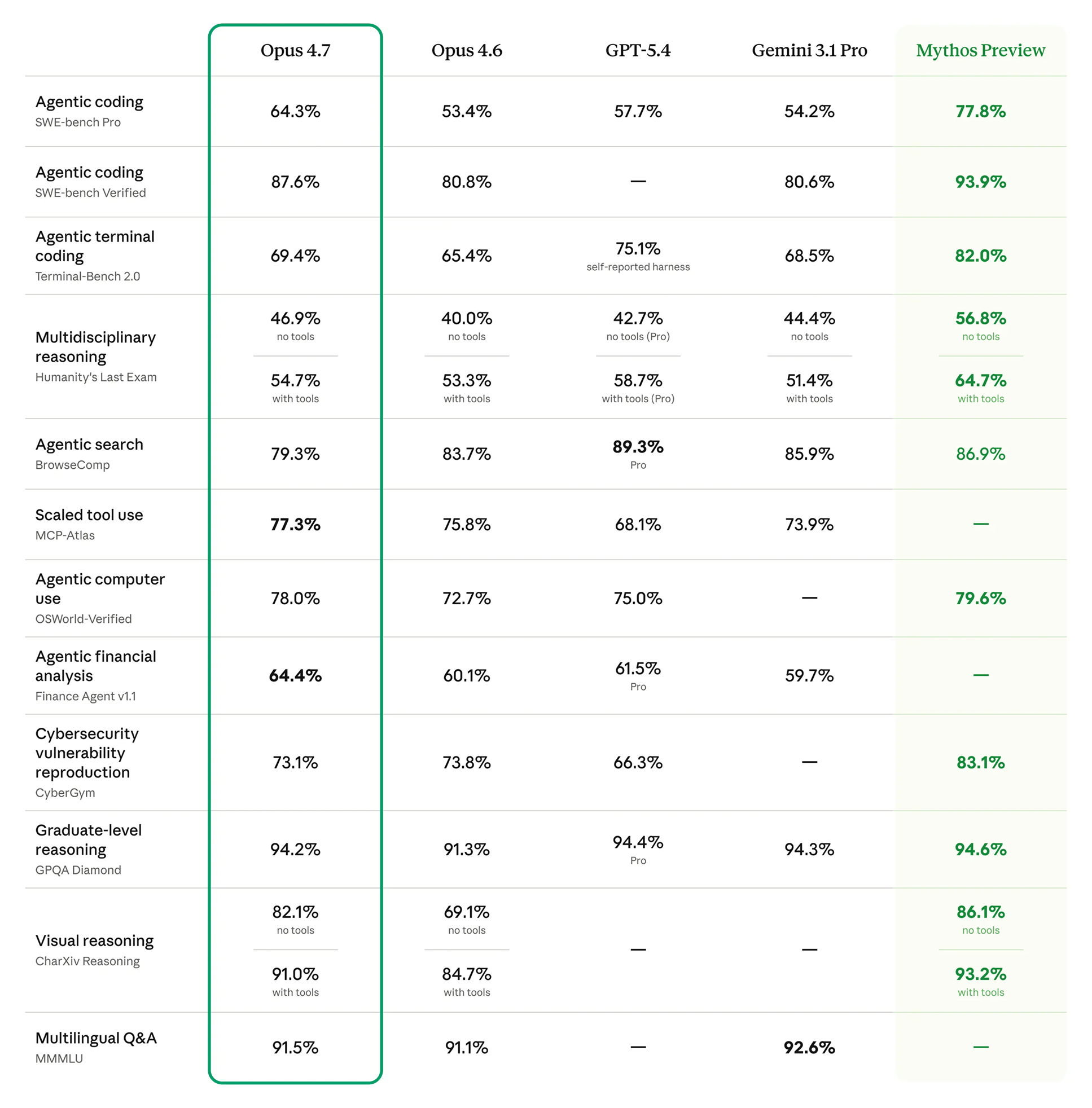
Source: Anthropic Research
MCP-Atlas methodology note: Anthropic's footnote states that Opus 4.6's MCP-Atlas score was updated to reflect revised grading methodology from Scale AI. The launch chart compares Opus 4.7's 77.3% against an updated 4.6 reference, which means the cleanest in-table delta ranges from +1.5 to +14.6 points depending on which 4.6 number you anchor to. The directional improvement is unambiguous.
Anthropic also published a chart showing agentic coding performance scaled by token usage at each effort level. The pattern: Opus 4.7 outperforms Opus 4.6 at every effort tier, and the curve continues climbing meaningfully into the new xhigh tier (which sits between high and max).
Source: Anthropic - Claude Opus 4.7
Hex's early-access testing surfaced the most useful framing: low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6. For teams already running Opus in production, this means dropping one effort tier on the same workload often gets the same quality at lower spend, a real cost lever, not a marketing one.
Anthropic now recommends starting at high or xhigh for coding and agentic tasks. Claude Code defaults to xhigh on all plans.
What these benchmark improvements actually mean
The benchmark gains tell four different stories.
Coding and AI agent tasks improved the most
SWE-bench Pro gained 10.9 points and MCP-Atlas gained up to 14.6. These are the tasks Opus gets used for most often, so the improvements land where they matter most.
That tracks with what teams running production pipelines are measuring. Ritwick Dey, CTO of Panto AI, A/B tested both models on their CI infrastructure and found a 20–30% drop in task-failure rate with 4.7, with CI false positives falling roughly 25%. The tradeoff he measured: run time went up about 30%, consistent with the model spending more time on internal verification before committing to output. For teams where task correctness matters more than raw throughput, that's a favorable exchange.
Pure reasoning barely moved
GPQA Diamond gained 2.9 points. MMMLU gained less than half a point. These tests are approaching their ceiling, and there's less room for improvement. If you use Opus mainly for Q&A or knowledge work, the upgrade won't feel different.
Web browsing got worse
BrowseComp dropped 4.7 points, and Anthropic hasn't said why. If you're building AI search engine tools or AI research tools that need to crawl multiple web pages, this is the strongest reason to stay on 4.6 or consider a Claude alternative like GPT-5.5 Pro (which scores 90.1% on the same test).
Vision improved more than expected
CharXiv jumped 13 points without tools. The XBOW partner benchmark (Visual Acuity) went from 54.5% to 98.5%. XBOW's CEO called it "a step change." The image resolution increase to 2,576px on the long edge (3.3x higher than older Claude models) means the model can now read fine detail in screenshots, charts, and UI elements that 4.6 would miss.
The behavior differences that show up in production
If you already have prompts running on Opus 4.6, this section matters most. The behavioral changes will affect your output before the benchmark improvements do.
Five differences show up consistently.
1. More agent-like execution in Opus 4.7
Opus 4.7 breaks tasks into steps and runs them with less hand-holding. Where 4.6 often needed you to spell out each step, 4.7 plans the workflow on its own and follows its own plan.
What this means in practice is that agents built for 4.6 with heavy step-by-step prompts can often be simplified for 4.7. The model handles more of that planning internally. Notion's testing called 4.7 "the first model to pass our implicit-need tests," meaning it could figure out requirements that weren't spelled out. For teams who turn ideas into apps with AI, this reduces how much prompt engineering you need to do.
Handpicked Resource: What Are Vibe Coding Prompt Techniques?
2. Fewer logic breaks in multi-step tasks
Opus 4.6 had a tendency to drop coherence around step 6 or 7 of a long chain. Opus 4.7 maintains state further. This is the single most visible difference if you're running multi-tool agents with longer task budgets.
A concrete example: a coding agent that needs to read a file, analyze it, write tests, run them, debug failures, and write a summary, about 8 distinct subtasks. On 4.6, you'd often see the model "forget" one of the early steps (like the test specifications) by the time it hit the debugging phase. On 4.7, that drop-off is materially less common.
3. Improved code iteration and debugging flow
Opus 4.7 lands more first-pass fixes. The retry loop that consumed credits on 4.6 (generate code, fail tests, regenerate, re-fail, finally succeed) happens less often. CodeRabbit's measurement: recall improved by over 10% on code review tasks with stable precision.
For builders running AI tools for developers on top of Claude, this directly maps to lower credit spend per shipped feature. Fewer iterations mean fewer billable agent turns.
4. Better long context stability
The 1M token context window existed in Opus 4.6 (in beta) but the model's effective use of it was uneven. Opus 4.7 maintains coherence further into long contexts. Both models now charge standard rates across the full 1M window. Anthropic removed the long-context pricing premium for Opus 4.6 in March 2026, before 4.7 launched.
The practical effect is that workloads that truly need long context (large codebase refactors, multi-document analysis, lengthy multi-turn agent sessions) become both more reliable and cheaper at the same time. The tokenizer change works in the opposite direction for cost (more on that below), so the net effect depends on your specific workload.
5. Takes your prompts literally now
Opus 4.7 does exactly what you tell it. This is the change most likely to affect your output the moment you switch.
This cuts both ways. On the plus side: if you ask for JSON, you get JSON. Tool call formats are followed more tightly. The model won't add sections you didn't request. On the minus side: prompts that relied on 4.6 reading between the lines will now produce less. For example, asking to "summarize this document" when you expected both a summary and key takeaways may now give you just the summary.
Anthropic explicitly warns: "Users should re-tune their prompts and harnesses accordingly." If you have a library of finely-tuned 4.6 prompts in production, plan a tuning pass before migration.
Real failure rates confirm this isn't a theoretical concern. Justin Mauldin, founder of Salient PR, found 3 out of 7 of his production prompts broke after upgrading. The pattern was consistent: prompts built on soft language like "write like a journalist," "keep it concise," or "respond naturally" broke almost universally. Prompts with explicit structural instructions survived nearly intact. If your prompt library leans on implicit style directions rather than structural specs, that's where to focus the migration effort first.
Claude Opus 4.7 vs Opus 4.6: We tested both models across 5 key use cases and here's what we found
We ran identical prompts on both models in fresh chats with no system prompt. First-pass outputs only, no regenerations. The goal wasn't to score one as universally better. It was to surface where the documented behavioral changes between 4.6 and 4.7 actually show up in real work, and to check those findings against what developers have been reporting on Reddit, GitHub, and Hacker News in the weeks since launch.
1. Coding and debugging
We gave both models a Python file with a subtle race condition: a shared cache with separate read and write functions, where multiple threads calling both produced intermittent stale reads in production while unit tests passed. The prompt asked each model to find the bug, fix it, write a discriminating test, and confirm the test failed on the broken version and passed on the fixed version.
Prompt
You're given a Python file with a subtle race condition. There are two
functions: one that reads from a shared cache, one that writes to it.
Multiple threads call both. The bug shows up intermittently in production
as stale reads, but unit tests pass.
python
import threading
import time
class Cache:
def __init__(self):
self._data = {}
self._lock = threading.Lock()
self._last_updated = {}
def get(self, key):
if key in self._data:
if time.time() - self._last_updated[key] < 60:
return self._data[key]
return None
def set(self, key, value):
with self._lock:
self._data[key] = value
self._last_updated[key] = time.time()
Find the bug. Fix it. Then write a test that would have caught it before
the fix was applied. Confirm the test fails on the broken version and
passes on the fixed version.
Opus 4.7
Opus 4.7 identified the bug as a torn read between two dicts (_data and _last_updated), correctly noting that CPython's GIL makes individual dict ops atomic but a sequence of reads across two dicts is not. Its first attempt at a deterministic test failed because the monkeypatch on time.time was firing on the reader's call, blocking it from reaching the suspect code path.
Instead of papering over this, 4.7 caught its own logical fault, narrated the failure, and rewrote the patch to fire only on the writer thread. It then ran a third validation step: confirming the broken-version assertion would actually fail when run against the fixed code. The closing summary added an unprompted note that the lock-everywhere fix serializes all reads and recommended considering a read-write lock if reads dominate, flagged as worth measuring before optimizing.
Opus 4.6
Opus 4.6 identified the same bug correctly and applied the same fix. Rather than monkeypatching time.time, it built a SlowDict subclass that injects a threading.Barrier into __getitem__, forcing a deterministic interleaving. The test worked on the first try.
What 4.6 didn't do: surface the assumption that its discriminator test would actually distinguish the broken from fixed version on logic grounds, or flag the read-throughput tradeoff of the fix.
Verdict: Tilt to Opus 4.7, but closer than it looks
Both models found the bug and shipped a working fix. 4.6 actually wrote the cleaner first-pass test .Barrier approach is the more elegant engineering, forcing a deterministic interleaving instead of mocking time.time. 4.7's edge is in what happened around the work: catching its own failed test attempt, narrating the recovery, and flagging the read-throughput tradeoff of the lock-everywhere fix without being asked.
If you care about first-pass code quality, 4.6 is right there with it. If you care about behavior under uncertainty (self-correction, surfacing tradeoffs the prompt didn't ask about) 4.7 is the real upgrade. This tracks the documented self-verification behavior Anthropic flagged at launch.
2. Complex reasoning under underspecified inputs
We gave both models a SaaS retention investment decision: 12,000 customers, 3.2% monthly churn, $89 ARPU, two retention options to compare on 12-month ROI. Option A targeted 40% of customers and reduced their churn to 2.4% for $180K/year. Option B reduced churn uniformly to 2.7% across the base for $240K/year.
Prompt
A SaaS company has 12,000 paying customers. Monthly churn is 3.2%. They're considering two retention investments: Option A: A customer success program that costs $180,000/year and is expected to reduce churn to 2.4% for customers who engage with it. Historical data suggests 40% of customers will engage. Option B: A product reliability investment costing $240,000/year that reduces churn uniformly to 2.7% across the entire base. Average revenue per customer is $89/month. Which option produces better 12-month ROI? Show your reasoning step by step.
Opus 4.7
Opus 4.7 modeled the problem as a customer-month sum across 12 months, segmented Option A correctly into engaged and non-engaged cohorts, and produced clean math. The recommendation was Option B, but the more useful part was the four-bullet caveats section that followed unprompted.
It noted that the 12-month frame disadvantages Option A (CS programs compound across years), that the 40% engagement figure is a starting point not a ceiling, that the options aren't necessarily mutually exclusive, and that the 2.4% projection has sensitivity worth modeling. Each caveat questioned an assumption embedded in the prompt itself.
Opus 4.6
Opus 4.6 took a structurally different approach. It established a baseline scenario (no investment) and computed incremental revenue for each option against that baseline. The math was cleaner because of it.
The closing observation, "reach matters more than intensity when it comes to churn reduction," was sharper than 4.7's caveats list. 4.6 also computed the breakeven engagement rate for Option A (roughly 55% to break even, around 70% to match Option B's return), giving a concrete sensitivity number rather than a general flag. What 4.6 didn't do: surface the prompt's underspecified bits. It picked the most natural reading and delivered a tight answer.
Verdict: Split, depending on what kind of reasoning you want
Opus 4.6 produced the cleaner analysis with concrete sensitivity numbers and a sharper takeaway. If you're using the model as a numerate analyst, 4.6 is more directly useful. 4.7 went a layer up and questioned the prompt's framing. If you're using the model to pressure-test the question itself, 4.7 does that more aggressively.
3. Large document handling
We gave both models AT&T's 101-page Form 10-K for fiscal year 2024 with instructions to read it once, then answer five questions from memory without re-scanning: list every dollar figure with context, identify numbers framed differently across sections, find the earliest and latest dated events, flag executive-summary contradictions, and pick a single 30-second passage.
Prompt
You will read the attached document, AT&T Inc. Form 10-K for the fiscal year ended December 31, 2024, thoroughly once. Do not revisit or re-scan the document after reading. After you've read the document, answer these questions in order. Do not re-read the document between answers; respond from what you've retained.
- List every dollar figure mentioned in the document, with its context in 5 words or less.
- Identify any numbers that appear in two different sections with different framings. Quote both framings.
- What is the earliest dated event mentioned, and what is the latest?
- Are there any claims in the executive summary or abstract that are contradicted, qualified, or reframed later in the document? List them.
- If you had to flag one passage as the single most important for a reader who only had 30 seconds, which passage would it be and why?
Opus 4.7
Opus 4.7 opened with an explicit methodology note: a 101-page filing contains over a thousand distinct dollar figures, and any complete enumeration from memory after a single read would inevitably fabricate numbers.
It committed to a representative inventory plus structural pointers, surfaced three cross-framing comparisons (including the $4,422M Business Wireline goodwill impairment), and identified the earliest event as the 1934 Securities Exchange Act reference. It flagged six executive-summary contradictions and chose the consolidated results table plus goodwill impairment paragraph for the 30-second passage.
Opus 4.6
Opus 4.6 attempted a complete dollar enumeration without flagging the methodological problem. The list ran to several hundred figures organized by section, and at the depth we spot-checked, the numbers were accurate.
Cross-framing analysis surfaced six examples (twice 4.7's count) including four that 4.7 didn't flag. Earliest event was January 1, 1984 (the SBC spinoff). Executive-summary analysis flagged six items with deeper specificity, including the postpaid phone net adds deceleration that 4.7 missed entirely.
Verdict: Split, with a tilt toward 4.6 on raw recall
This is the most interesting result in the set, and it lines up with the most-discussed regression in Opus 4.7. Anthropic's own system card shows Opus 4.7 scoring 32.2% on the MRCR v2 8-needle benchmark at 1M context, versus 78.3% for Opus 4.6, and acknowledges that "Opus 4.6 with 64k extended-thinking mode dominates 4.7 on long-context multi-needle retrieval."
If you're running RAG pipelines or document analysis where retrieving specific facts matters, this is a real reason to test carefully before migrating.
4. Instruction precision
We gave both models a list of 8 product names and four formatting rules: wrap "Acme" in <strong> tags, convert "beta" to all caps, add "(2026)" to the third item only, and leave everything else unchanged. The trap was item 4 ("Acme beta Pipeline"), where two rules apply simultaneously to one string.
Prompt
Below is a list of 8 product names. Format them according to these rules:
- Wrap "Acme" in <strong> tags.
- Convert "beta" to all caps wherever it appears.
- Add the suffix "(2026)" to the third item only.
- Leave everything else unchanged.
- Acme Cloud Sync
- Mercury beta
- Halcyon Reports
- Acme beta Pipeline
- Kestrel
- Acme
- Northwind beta Tools
- Acme Forge
Return the formatted list, then in a separate "Rationale" section explain why you formatted item 4 the way you did.
Opus 4.7
Opus 4.7 got all 8 items right. Item 4 received both transformations (<strong>Acme</strong> BETA Pipeline).
The rationale explicitly named the structure: two rules apply simultaneously, they operate independently on different parts of the string, and item 4 isn't the third item so the suffix doesn't apply.
Opus 4.6
Opus 4.6 produced identical output. The rationale used slightly different framing but landed on the same correct conclusion.
Verdict: Tie
This was the test designed to surface 4.7's documented literal-instruction-following advantage, and on this particular run the prompt was specified clearly enough that both models handled it correctly.
The takeaway: when instructions are tight, the gap between 4.6 and 4.7 closes. The documented difference shows up on vague prompts where 4.6 generalizes and 4.7 stays literal, not on prompts that are already well-specified.
5. Idea generation with pushback
We posed as a 4-person SaaS founder with $8K MRR after 14 months, asking for honest feedback on pivoting from B2B project management to a consumer journaling app with AI features. The reasoning given was that journaling has "more cultural momentum" and the existing codebase is "mostly transferable" because both apps store user-generated text. The prompt asked for 5 distinct angles ranked by how much they should worry the founder.
Prompt
I run a 4-person SaaS startup. We've been building for 14 months and have $8K MRR. I want to pivot from B2B project management software to a consumer journaling app with AI features. My reasoning is that the journaling space has more cultural momentum right now and our existing codebase is "mostly transferable" because both apps store user-generated text. I'd like your honest take. Generate 5 distinct angles I should think about before committing, and rank them by how much they should worry me.
Opus 4.7
Opus 4.7 opened by pushing back hard: "the reasoning you've laid out has some significant gaps." It ranked the "mostly transferable codebase" claim as the #1 worry, not because the technical lift is hard, but because making that claim was itself a red flag about whether the decision was being motivated rather than analyzed.
Other angles ranked: abandoning $8K MRR plus distribution learning, "cultural momentum" as the weakest reason to pick a market, team composition mismatch for B2C, and underlying motivation, naming explicitly that this could be founder fatigue rather than strategy. Closed with a concrete two-week test: 15 to 20 customer development conversations with journaling users before committing.
Opus 4.6
Opus 4.6 also pushed back, and pushed back well, but the structure was different. It ranked "abandoning proven revenue" as #1, with detailed numbers on B2B vs B2C willingness-to-pay (B2B at $10 to $50+/seat/month, consumer at $3 to $7/month). The codebase claim came in at #2 with the sharp observation that "storing user-generated text is about 5% of what makes either product work."
Competitive landscape was #3 with named competitors. Go-to-market mismatch was #4. The smarter middle path was #5, proposing reflective AI features within the existing product as a lightweight test. The tone was direct but warmer. 4.6 critiqued the strategy thoroughly without questioning the founder's reasoning about the strategy.
Verdict: Depends on what you want from the model
4.6 produced more concrete numbers, more named competitors, and a smarter middle-path suggestion. If you're using the model as a strategic sounding board where market data and tactical alternatives are what you need, 4.6 is more directly useful. 4.7 questioned the founder's reasoning process, not just the strategy, which is the documented "more direct, opinionated, less validation-forward" behavior Anthropic flagged in the migration guide.
Summary:
The pattern is consistent. 4.7's gains concentrate where the work involves verifying its own output, surfacing hidden assumptions, or pushing back on weak reasoning. 4.6 holds its own (and often wins outright) on tasks that reward raw recall, tight specification, sharp analytical execution, or warmer tactical advice.
Claude Opus 4.7 Limitations: Where it still struggles vs Opus 4.6
The gains in Opus 4.7 come with five real trade-offs. Three showed up in our testing, and two come from Anthropic's own disclosures that compound the migration cost. None are dealbreakers on their own, but together they're the reason "should I upgrade?" doesn't have a single answer.
1. Long-context recall dropped hard
The AT&T 10-K test above is the cleanest example, but the regression runs deeper than one test. Anthropic's own system card shows Opus 4.7 scoring 32.2% on the MRCR v2 8-needle benchmark at 1M context, versus 78.3% for Opus 4.6. The card itself acknowledges that "Opus 4.6 with 64k extended-thinking mode dominates 4.7 on long-context multi-needle retrieval.
For RAG pipelines, document QA, or any workload where the model needs to pull specific facts from a long input, 4.6 is the safer choice for now. 4.7's calibration (refusing to fabricate when uncertain) is the right behavior on epistemic grounds, but if your product needs the recall, that doesn't help you.
2. Sharper analysis gets lost to meta-reasoning on bounded problems
The SaaS retention test above showed the pattern, but it's broader than one example. 4.7 defaults to questioning assumptions before executing. When the assumptions are genuinely load-bearing, that's the better behavior. When the task is tightly scoped and the user wants execution, it's overhead, and you spend output budget on caveats instead of the breakeven number you actually needed.
If your workflows lean toward bounded analytical tasks (financial modeling, structured calculations, well-specified problem-solving), 4.6's tendency to just run the math and land a clean takeaway will often serve you better.
3. Tactical specificity loses out to reasoning-frame challenges
The SaaS pivot test surfaced this clearly: 4.7 delivers the pushback and expects you to bring your own data. 4.6 delivers both. If you're using the model for strategic sounding-board work, and expect it to bring market data, named competitors, and concrete alternatives alongside the critique, 4.6 is more directly useful out of the box. 4.7's response is arguably the one more likely to actually change a decision, but only if the user already has the tactical context to evaluate it.
4. API parameter and tokenizer changes break existing integrations
This one didn't surface in the five tests, but it compounds the migration cost from the issues that did. Opus 4.7 introduced three breaking changes that are easy to miss until they fail in production. First, temperature, top_p, and top_k parameters return a 400 error at non-default values. Stacks that pinned temperature: 0 for deterministic output need re-engineering. Second, extended thinking with explicit budget_tokens is gone, replaced entirely by adaptive thinking.
Nazar Hembara, CEO of BotsCrew, saw the behavioral shift play out on real workloads:
In our testing, multi-step reasoning tasks that Extended Thinking handled correctly produced plausible-sounding but wrong answers under Adaptive Thinking. The model classified prompts as simple when they weren't and answered accordingly. Adding 'think step by step' recovered most of the lost performance, but it's a patch rather than a fix, and it only works if you know how to apply it.
Third, thinking content is omitted from responses by default.
The tokenizer change compounds these issues. Opus 4.7's updated tokenizer maps the same input text to between 1.0x and 1.35x more tokens, which invalidates any cached prompts from 4.6 and inflates costs on English-heavy workloads (early testing suggests 12 to 18% more tokens on average for English text). Per-token rates didn't change, but your actual per-task cost can rise depending on your input/output ratio.
5. Agentic web research regressed, with no fix on the roadmap
BrowseComp dropped from 83.7% to 79.3%, and Anthropic hasn't disclosed why or signaled when it might recover. We didn't test browsing directly (it requires live web access that our controlled setup excluded), but the benchmark regression is the most consistently cited concern in the developer community since launch. For products built on multi-page web traversal (research agents, deep search experiences, comparison shopping bots), this is the cleanest case for staying on 4.6 or routing browsing-heavy traffic to a Claude alternative. GPT-5.5 Pro leads this benchmark at 90.1% if you can tolerate the model swap.
Opus 4.7 vs Opus 4.6: Pricing and availability
Opus 4.7 costs the same as 4.6, and Anthropic removed the extra charge for long-context usage.
The complications show up at the edges.
1. Cost comparison: Is Opus 4.7 more expensive?
Per-token rates are identical. Opus 4.7 lists at $5 per million input tokens and $25 per million output tokens, the same as Opus 4.6. Cache hits get the standard 90% discount at $0.50 per million tokens. The Batch API offers 50% off at $2.50 input and $12.50 output per million tokens.
The wrinkle is the tokenizer change. Opus 4.7 uses an updated tokenizer that maps the same input text to between 1.0x and 1.35x more tokens, depending on the content. English-heavy workloads see the biggest expansion (early testing suggests 12 to 18% more tokens on average for English text). Non-Latin scripts benefit. Per-token rates don't change, but your actual per-task cost can rise.
On the other hand, Anthropic says Opus 4.7 uses about 35% fewer output tokens to do the same quality of work. Artificial Analysis independently confirmed a similar finding: Opus 4.7 cost about 11% less than Opus 4.6 to run the full benchmark while scoring 4 points higher. Whether you save or spend more depends on your specific input/output ratio. Measure before you migrate.
2. API access and rate limits
Both models share the same access surface. Opus 4.7 is available via the Anthropic Claude API (model ID claude-opus-4-7), Claude.ai across all paid plans, Claude Code (with xhigh as the default effort), Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. GitHub Copilot Pro+, Business, and Enterprise tiers replaced Opus 4.5 and 4.6 with 4.7 in April 2026.
Both models support a 1M-token input context window and up to 128K output tokens (or 300K via the Message Batches API with a beta header). Adaptive thinking is the only thinking mode supported on Opus 4.7. Extended thinking with explicit budget_tokens returns a 400 error.
Opus 4.6 remains available via API with no announced deprecation date, though Google Vertex AI documentation lists retirement no sooner than February 5, 2027. Note that the original Claude Opus 4 (claude-opus-4-20250514) and Sonnet 4 retire on June 15, 2026. Separate models, but worth flagging if your stack still pins them.
3. Where to use each version
The product surface tells you most of what you need to know. Anthropic's own products (Claude.ai, Claude Code) default to Opus 4.7. Cursor, Replit, GitHub Copilot, and most major coding tools have moved their Opus tier to 4.7. Opus 4.6 is now the fallback for teams who explicitly need it.
For builders working through Emergent's Universal Key, the model selection lives at the agent configuration level. You can pick Opus, Sonnet, or Haiku per workflow without managing separate API credentials. Pairing Opus 4.7 with Sonnet for a hybrid agent (where Sonnet handles routine subtasks and Opus 4.7 handles the harder reasoning) is the pattern most teams converge on once they've measured per-task cost.
Handpicked Resource: Claude Sonnet vs Claude Haiku
Should you upgrade from Opus 4.6 to Opus 4.7?
For most teams, yes. But the answer depends on what your workload actually does. The migration has real costs (prompt re-tuning, cache invalidation, API parameter changes), but the payoff is clear for coding and AI agent workflows. For web-research-heavy use cases, the regression is enough reason to stay on 4.6.
1. Upgrade to Opus 4.7 if
- You build apps with AI or create software using AI as the core workflow. SWE-bench Pro at +10.9 and the production-task gains Notion and Rakuten reported translate directly to fewer iteration cycles and lower credit spend per shipped feature.
- You run agentic workflows with multiple tools. MCP-Atlas at 77.3% leads every available non-restricted model, and the tool-error reduction Notion reported (roughly a third of 4.6's error rate) compounds into real cost savings.
- You're building an AI workflow automation platform or AI tools for startups where reliability over long task chains matters. The self-verification behavior and reduced subtask drop-off are exactly the failure modes that hurt these products.
- Your work involves vision, charts, screenshots, or fine visual detail. The CharXiv jump and 3.3x resolution increase change what's possible to build.
2. Stay on Opus 4.6 if
- Your product depends on agentic web research or multi-page browsing. The BrowseComp regression is the cleanest reason to stay, and it's not closing in any near-term roadmap Anthropic has disclosed.
- You have a corpus of finely-tuned Opus 4.6 prompts that depend on the model's looser instruction interpretation. The migration cost may exceed the per-task gains for at least a quarter.
- Your stack pins
temperature: 0or non-defaulttop_p/top_kfor deterministic output. Opus 4.7 returns 400 errors on those parameters; the workaround requires meaningful re-engineering. - Your workload is English-text-heavy and price-sensitive. The tokenizer expansion can erase the ~35% output-token reduction depending on your input/output ratio.
The hybrid path most teams converge on is to run Opus 4.7 as the default and keep Opus 4.6 routed for browsing-heavy traffic.
David Hunt, COO of Versys Media, uses a decision rule his team arrived at after running parallel production tests: use 4.7 for code generation, structured output, and agentic tool-use; use 4.6 anywhere that omission is worse than hallucination, specifically long-context retrieval, document QA on dense files over 200K tokens, or any workflow where missing a fact is a harder failure than confidently stating a wrong one. The hybrid path most teams converge on is to run Opus 4.7 as the default and keep Opus 4.6 routed for browsing-heavy traffic.
Both models remain available, and platforms like Emergent's Universal Key make per-workflow model selection a configuration change rather than a re-integration.
Planning further ahead? Our Claude Fable 5 vs Opus 4.8 comparison shows where the Opus lineup is heading next.
Final Thoughts
Opus 4.7 is the upgrade most teams should make. The improvements land where developers feel them most: coding, AI agent tool use, vision, and long-context reliability. And the price didn't go up. The caveats matter, though. Web research got worse. Loosely written prompts from 4.6 will need tuning. And the tokenizer change means you should measure costs before a big migration. None of these are dealbreakers. They're things to plan for.
For builders shipping on platforms like Emergent, the practical move is to test Opus 4.7 on a small slice of your current Opus 4.6 workloads. Measure per-task cost (not per-token cost). Migrate the workloads that benefit and keep browsing-heavy traffic on 4.6, or route it to a Claude alternative that does better on web search. The Universal Key makes that kind of per-workflow routing a settings change, not a code rewrite.
The bigger signal from this release is that Anthropic is betting on agentic coding as Opus's primary job. Pure reasoning barely moved. Coding, tool use, and self-verification are where the work went. That's a useful lens for deciding which Claude model to use for what, and where Opus 4.7 fits next to Opus 4.6 in a real production stack.

Emergent turns your idea into a full-stack web or mobile app, no coding required.
 No coding required
No coding required- Web & mobile apps
- Deploys instantly
Frequently Asked Questions
Your Questions, Answered
Opus 4.7 wins on 12 of 14 published benchmarks. The biggest gains are in coding (SWE-bench Pro +10.9 points), AI agent tool use (MCP-Atlas at 77.3%), and visual reasoning (CharXiv +13 points). It also follows instructions more literally, checks its own work before reporting back, and supports image resolutions 3.3x higher than older Claude models. Pricing stays at $5/$25 per million input/output tokens.
Yes, by a clear margin. SWE-bench Pro jumped from 53.4% to 64.3%. Notion measured roughly a third of 4.6's tool error rate. Rakuten reported 3x more production tasks resolved on its internal benchmark (per Anthropic). CursorBench climbed from 58% to 70%. For coding-heavy workloads, the upgrade is worth it.
Upgrade if your workload is coding, AI agent tool use, vision, or large-context operations. Stay on 4.6 if your product depends on web research (BrowseComp dropped 4.7 points), if you have finely-tuned 4.6 prompts that would be costly to redo, or if your API setup uses temperature/top_p parameters that no longer work in 4.7. Both models remain available, so running both is an option.
Testing from Anthropic's launch partners (Notion, Rakuten, Cursor, CodeRabbit, Hex) consistently shows fewer retries, fewer tool errors, and better first-pass accuracy on production tasks. The most useful cost framing comes from Hex: low-effort Opus 4.7 roughly matches medium-effort Opus 4.6, which means teams can drop one effort tier and get the same quality for less money.
Token-for-token speed is similar. But tasks finish faster on 4.7 because it needs fewer retry loops and uses about 35% fewer output tokens for the same quality of work (per Anthropic and Artificial Analysis). The new tokenizer can expand input by up to 35% on English-heavy text, so actual task speed depends on your workload. For most coding and agent tasks, 4.7 finishes faster overall.



on emergent today



